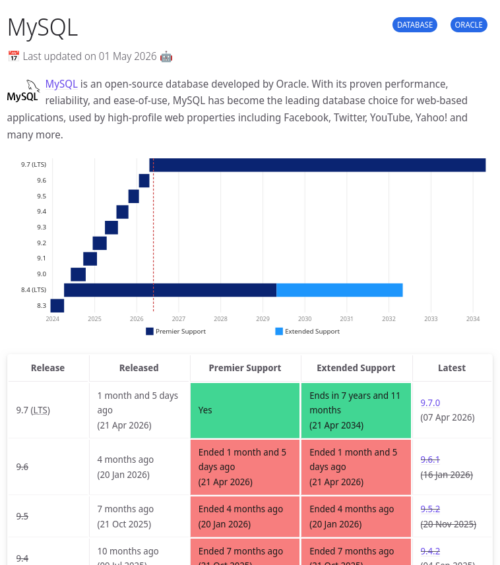
I don’t use chroot, but the default setup for modern versions of FPM already compartmentalizes everything adequately for example, the private /tmp directory. I agree with others that chroot is an outdated way of doing things.
Also, I use SELinux…yet another way of achieving many of the same goals of chrooting. I’d highly recommend setting up SELinux if you are not already using it. If you’re concerned enough about security that you’d even think of chrooting php-fmp, you probably want to set up SELinux and have it on «Enforcing» (it’s useless on «Permissive» mode, that’s really only suitable for the configuration phase of test servers.) Not only will it provide security with PHP, but you get a whole bunch of other security benefits of it.
I have done some pretty sophisticated things with a web server under SELinux, requiring me to manually change a number of policies, and while I have had a few prolonged sessions of frustration, maybe 3-4 hours at a time of banging my head against the wall trying to get the permissions set up properly, it is totally worth it. It’s all up-front work, and once you learn how to do it it’s very easy.