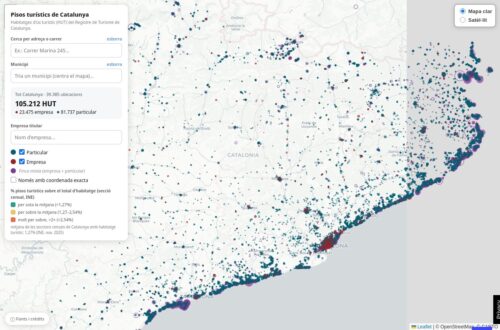
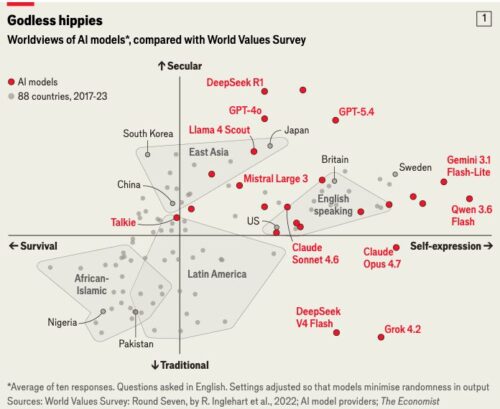
La máquina rota de comprender

la mal llamada “IA” lleva cuatro años faltando a todas sus promesas. Iba a sustituir 300 millones de puestos de trabajo (no ocurrió), iba a curar el cáncer (tampoco), iba a sustituir a todos los programadores (hoy hay más que nunca) y a incrementar la productividad (no lo ha hecho). Iba a crear ejércitos autónomos (¿Anybody?) y a traer la “singularidad”, o el fin de la historia, el momento en que una superinteligencia haría innecesario al género humano. ¿Dónde se encuentra esa criatura hoy? Ni está ni se la espera.
Por supuesto que hay gente que lleva mucho tiempo explicando que la IA no es lo que dicen sus promotores; que ninguna tecnología que se limite a computar el lenguaje puede razonar realmente; que la naturaleza probabilística de los LLMs hace que sea imposible que dejen de alucinar y que por esa razón tienen muy mal encaje en el sistema productivo, que necesita certezas; que no existen barreras de entrada que permitan monopolizar esta tecnología de la manera en que otros gigantes tecnológicos lo hicieron en el pasado y que no es posible generar un modelo de negocio rentable para las empresas de la IA, mucho menos uno que justifique la valoración billonaria de algunas compañías.
Como consecuencia, lo que está ocurriendo en los mercados financieros solo se puede entender como una inmensa burbuja de expectativas en la que el dinero se mueve en círculos entre unas cuantas empresas sin llegar nunca a encontrar un cliente real. Es la enésima versión de una burbuja que lleva hinchándose desde que Internet cambió la naturaleza de la sociedad.