

Difference between checkpoint , lora, model…
Technically they’re all machine learning models, but checkpoints are usually referred to just as models. All models are static, meaning they only know what they were trained on. In order for them to learn something new, they have to be (re)trained again, also known as finetuning.
Their differences in very rough terms:
Checkpoints are the big models that make images on their own.
Loras and all their variations like Lycoris are «mini models» that plug into a checkpoint and alter their outputs. They let checkpoints make styles, characters and concepts that the base checkpoint they’re used on doesn’t know or didn’t know very well.
Hypernetworks are an older and not as good implementation of the same paper and same concept as Loras.
Textual Inversions are sort of bookmarks or compilations of what a model already knows, they don’t necessarily teach something new but rearrange stuff that a model already knows in a way that it didn’t know how to arrange by itself.
SD 1.x, SD 2.x and SDXL are both different base checkpoints and also different model architectures. Think of them maybe as non backwards compatible consoles if that’s easier to understand. SD 1.5 is say both the NES itself but also one game for it. All SD 1.x based models are compatible with SD 1.x Loras and models for extensions like ControlNet. SD 2.X is the SNES, it’s a different architecture so 1.x models won’t be compatible with it, same for SDXL if you say that’s like the N64.
ControlNet models are also machine learning models that inject into the Stable Diffusion process and control the denoising process, they’re used with an image made by preprocessor. That image is be used to guide and control that denoising process, also hence the name.
All these models come in safetensors format. Safetensors is the standard for machine learning models, since they only contain the necessary data for diffusion, hence their name. .ckpt is the old model format that’s outdated, because it’s an unsafe format that can contain and execute malicious code.
Pruned models are models that have unnecessary weights and data removed. Weights are part of what the model learned in order to denoise noise to make an image. Say a model has a weight for alien = 0.00000000000000000001, it’s so minimal that it won’t do anything, but it’s still taking up space. Now multiply that for a lot of more useless weights, pruning removes all of them so only the relevant data is left.
FP16 models are smaller than FP32 models because they have lower precision, it’s basically like calculating pi with less numbers, you’ll get close enough results, almost exactly the same in most cases, but still not as precise. Yet the images from FP16 models are also not that different or worse, and A1111 converts models to FP16 by default when loading them anyway, for faster speed.
To use a model, place them in their specific folder inside the UI you’re using. For A1111 they go in stable-diffusion-webui\models in self explanatory folders for Lora, etc. and in stable-diffusion-webui\models\Stable-diffusion for checkpoints.
Both checkpoints and Loras can be used either for poses or for styles, depending on what they were trained on. Pose Loras are a thing for example.
The reason for your results is because you’re using SD 1.5 as a checkpoint. The base SD 1.5 checkpoint is almost a year old and the Lora you’re using was trained using not only newer checkpoints, but also checkpoints trained better on anime. I recommend a newer anime checkpoint for the image you’re trying to make. The base model field on Civitai models is really more like base architecture. Also it’s recommended to not go below 512 in resolution for SD 1.x models and not below 1024 for SDXL models.
Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared
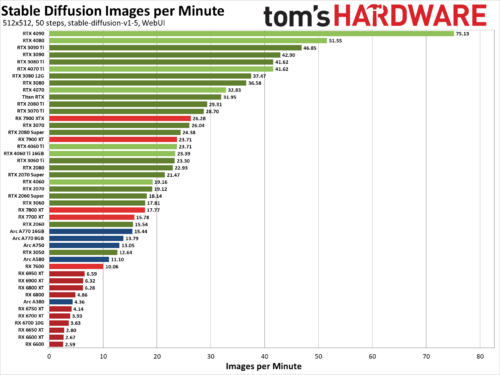
We’ve benchmarked Stable Diffusion, a popular AI image generator, on the 45 of the latest Nvidia, AMD, and Intel GPUs to see how they stack up. We’ve been poking at Stable Diffusion for over a year now, and while earlier iterations were more difficult to get running — never mind running well — things have improved substantially. Not all AI projects have received the same level of effort as Stable Diffusion, but this should at least provide a fairly insightful look at what the various GPU architectures can manage with AI workloads given proper tuning and effort.
The easiest way to get Stable Diffusion running is via the Automatic1111 webui project. Except, that’s not the full story. Getting things to run on Nvidia GPUs is as simple as downloading, extracting, and running the contents of a single Zip file. But there are still additional steps required to extract improved performance, using the latest TensorRT extensions. Instructions are at that link, and we’ve previous tested Stable Diffusion TensorRT performance against the base model without tuning if you want to see how things have improved over time. Now we’re adding results from all the RTX GPUs, from the RTX 2060 all the way up to the RTX 4090, using the TensorRT optimizations.
For AMD and Intel GPUs, there are forks of the A1111 webui available that focus on DirectML and OpenVINO, respectively. We used these webui OpenVINO instructions to get Arc GPUs running, and these webui DirectML instructions for AMD GPUs. Our understanding, incidentally, is that all three companies have worked with the community in order to tune and improve performance and features.