AntiRender


Upload an architectural render. Get back what it’ll actually look like on a random Tuesday in November.
No sunshine. No happy families. No impossibly green trees. Just cold, honest, depressing reality.

Upload an architectural render. Get back what it’ll actually look like on a random Tuesday in November.
No sunshine. No happy families. No impossibly green trees. Just cold, honest, depressing reality.
…cuando el coste de redactar una alegación, una reclamación o una solicitud tiende a cero, el volumen tiende a infinito.
Hasta ahora, el freno natural para el ciudadano era el esfuerzo. Rellenar formulario, entender normativa, escribir con cierto orden, invertir una tarde, etc. La fricción era el filtro.
Resumiendo, diría que esto es lo que pasará:
Explosión de expedientes automatizados. No porque la gente sea más conflictiva, sino porque el coste marginal es cero.
Necesidad de automatizar también la respuesta. Si la entrada es IA, la salida tendrá que ser IA. No puedes pretender que humanos procesen a mano lo que máquinas generan en masa.
Cambio en los filtros y criterios. Cuando la fricción desaparece, hay que diseñar nuevos mecanismos de priorización, validación o cribado.
Riesgo reputacional para el sector público. Si los tiempos se disparan, la percepción pública será de más incompetencia, aunque el problema sea estructural.
You may use who to check which users are logged in:
who
You can log-out the user by sending the KILL signal to the user-process with:
sudo pkill -KILL -u
En Desde el jergón pone en valor un rock madrileño que conformó gente como Cucharada, Leño, Asfalto, Mermelada, Topo, Burning, Moris (argentino que supo cantarle a la capital como pocos)… “A veces se da una idea de que en Madrid no había nada de música antes de la Movida. Usted perdone, antes de la Movida y sus colores el panorama en Madrid no era tan gris como se pinta. Había muchos grupos haciendo cosas, a pesar de las dificultades”. Cuando corrían los mejores años de Los Enemigos, la Movida ya estaba institucionalizada y los grupos cobraban unos cachés generosos. Mientras bandas de pop de aquella época alardeaban de tocar lo justo, Los Enemigos se pasaban seis horas al día ensayando. “No me parecía ni medio normal esto del amateurismo: hombre, si estás en un grupo, por lo menos afina, y sobre todo cuando estaban ganando una millonada contratados por ayuntamientos. Creo que además se ha sobredimensionado mucho todo el tema de que Madrid era el centro del universo.
I can hear the whingeing already: Nothing happens in this novel.
…we’ve got a bookish and earnest male protagonist and author’s proxy (Auster is a family name in the novel). We’ve got narrative instabilities that have us reading closely from Baumgartner’s point of view and then from some offstage “Pigs in Space”-type narrator’s: “Perhaps this odd confabulation will help the reader understand our hero’s state of mind at that particular moment.” Auster also splices in poems and pieces written by Baumgartner and his dead wife, Anna; forays into their past; and extended metaphors that require some unpacking. So it’s definitely a Paul Auster novel. Albeit more tender and less playful than some of his other work.
…who lost his wife nearly 10 years ago in a freak accident and has been caught between hanging on and letting go — or even pushing away — ever since. He has been severed from something essential but still feels its presence, much like the experience of phantom limb syndrome…
The novel walks us through what he thinks about and, more important, how he thinks. How his thoughts assemble and fall apart, how they produce a kind of cumulative power…
“Baumgartner” opens with Sy burning his hand on a pot handle, falling down the stairs and forgetting to call his sister. He’s trying to work, but the phone keeps ringing. The UPS lady shows up to deliver books Sy doesn’t want but has ordered just to ensure she comes to his door. In sum: Sy is old, lonely, frail, and his life is starred with these small events in a constellation that proves explosive enough on this morning to push him out of his emotional impasse. It also pushes the novel into gear to begin exploring and excavating Sy’s memories.
Hablemos de los contables. Cuando llegaron las hojas de cálculo, pese a la revolución que supuso para la contabilidad, los contables no desaparecieron. Al contrario: aumentó la cantidad de gente que hacía tareas contables. Lo que sí cambió fue la satisfacción de esas personas toda vez que el software se quedó con la parte interesante del trabajo interesante (análisis) y los humanos con lo repetitivo (introducir datos en un formulario).
La IA ya programa por nosotros. El placer de crear desde cero seguirá existiendo, pero ocupará menos espacio. El rol del humano va a pivotar hacia la revisión de software producido por la máquina, afinar prompts e integrar sistemas (quizá las tareas de devops y soporte sean una suerte de último foso de defensa para roles técnicos). ¿Les va a gustar? Probablemente no, probablemente desprecien esa labor tanto como desprecian actualizar tickets en Jira, porque la magia del rol que han hecho durante décadas, la resolución de problemas, el reto intelectual, va a ser resuelta por la máquina. La parte intelectualmente reconfortante se la queda la máquina, justo como le pasó a los contables.
Es cierto que la ansiedad y la depresión juveniles diagnosticadas aumentaron más o menos al mismo tiempo que se generalizó el uso de las redes, entre 2010 y 2015. Pero en esos años ocurrieron otras cosas, como que la crisis económica empujó a muchas familias a situaciones agobiantes de precariedad, y que en EEUU (país donde se originan muchos de estos estudios) empezaron a hacer revisiones de salud mental a toda la población adolescente.
Resulta difícil asimilar que Sánchez afirme “defender nuestra soberanía digital contra cualquier tipo de coerción extranjera” mientras su Gobierno no ha sido capaz de dejar de usar X como medio principal de difusión rápida, o de abrir cuentas oficiales en una alternativa europea (y libre, y descentralizada) como Mastodon. Resulta difícil creer que dejar de depender de grandes tecnológicas estadounidenses sea una prioridad cuando las instituciones públicas españolas siguen regando con miles de millones cada año a Google, Microsoft y Amazon para contratar su infraestructura digital. Y resulta sintomático que en el paquete de medidas para salvarnos de las redes sociales corporativas no haya ninguna destinada a que tengamos espacio digital público donde refugiarnos.
Si realmente queremos apoyar el bienestar joven, antes de prohibir las redes sociales, podríamos, por ejemplo, prohibir los desahucios, la pobreza infantil y la cisheteronormatividad.
Australia fue el primer país del mundo en impedir, desde el pasado diciembre, el acceso a las redes a millones de menores. No hay, por tanto, demasiada experiencia previa sobre un experimento similar. Ni siquiera existe consenso científico sobre si los móviles son buenos o malos a esa edad (o a cualquier otra). Un estudio publicado este mes por la Universidad de Mánchester siguió la evolución de 25.000 niños y niñas de entre 11 y 14 años a lo largo de tres años, y concluyó que ni las redes ni los videojuegos se relacionan con el empeoramiento de su salud mental. El debate se suele centrar en los efectos psicológicos de la tecnología, pero puede generar otro tipo de problemas. Y dejando aparte los informes, sobre lo que sí existen evidencias es de la mala fe de las plataformas, que fomentan la violencia, el acoso, la sexualización, la polarización, el engaño y la adicción de los menores por el bien del negocio. La discusión sobre las puertas y el campo es tan vieja como internet, y viene acompañada por la hipervigilancia ante una potencial pérdida de libertades. Porque, ¿quién decide qué es una red social?, ¿qué órgano la supervisa?, ¿cómo garantizar que actúa de forma efectiva, pero sin extralimitarse? También hay que preguntarse cómo podemos impedir que caigan en otras tecnologías inseguras para acceder a lugares aún más peligrosos y ocultos de internet. Y, sobre todo, de qué manera proteger su derecho a aprender, crear, relacionarse, informarse, expresarse y divertirse. Muchas cuestiones complicadas pueden ser ciertas a la vez: hay verdad en que las redes son atroces, pero también en la cuestión que plantea Ezra Scholl, un quinceañero australiano cuadrapléjico, en The Guardian: “¿Qué pasa con quienes estamos aislados?

Paul Auster’s brilliant eighteenth novel opens with a scorched pot of water, which Sy Baumgartner – phenomenologist, noted author, and soon-to-be retired philosophy professor – has just forgotten on the stove.
Baumgartner’s life had been defined by his deep, abiding love for his wife, Anna, who was killed in a swimming accident nine years earlier. Now 71, Baumgartner continues to struggle to live in her absence as the novel sinuously unfolds into spirals of memory and reminiscence, delineated in episodes spanning from 1968, when Sy and Anna meet as broke students working and writing in New York, through their passionate relationship over the next forty years, and back to Baumgartner’s youth in Newark and his Polish-born father’s life as a dress-shop owner and failed revolutionary.
Pendant longtemps, les bibliothèques étaient des lieux destinés à une élite savante. Jusqu’au XIXe siècle, elles étaient souvent réservées aux chercheurs, religieux, ou membres de l’administration. Les collections étaient précieuses, rares, et peu accessibles au grand public.
Avec les lois sur l’instruction obligatoire (notamment la loi Ferry de 1881-1882), l’alphabétisation progresse, et la demande pour un accès à la lecture se fait plus forte. Des bibliothèques municipales commencent alors à se développer dans les villes, mais restent encore souvent modestes.
Un tournant important a lieu en 1945, avec la création de la Direction des bibliothèques de France. L’objectif : moderniser, structurer et développer un véritable réseau de bibliothèques publiques.
Le terme “médiathèque” apparaît dans les années 1970. Il marque un changement profond : ces nouveaux lieux ne proposent plus seulement des livres, mais aussi d’autres médias – disques, films, cassettes vidéo, puis CD et DVD. C’est la naissance de la bibliothèque multisupport, tournée vers tous les types de cultures.
La médiathèque devient aussi un lieu de vie, d’animation et de diffusion culturelle. On y organise des expositions, des conférences, des projections. Elle s’adresse à un public plus large, de tous âges et de toutes origines sociales.
A few months ago I was standing on the 13th floor balcony of the Google New York 9th St office staring out at Lower Manhattan. I’d been deep in the weeds of a secret project using Nano Banana and Veo and was thinking deeply about what these new models mean for the future of creativity.
I find the usual conversations about AI and creativity to be pretty boring – we’ve been talking about cameras and sampling for years now, and I’m not particularly interested in getting mired down in the muck of the morality and economics of it all. I’m really only interested in one question:
What’s possible now that was impossible before?
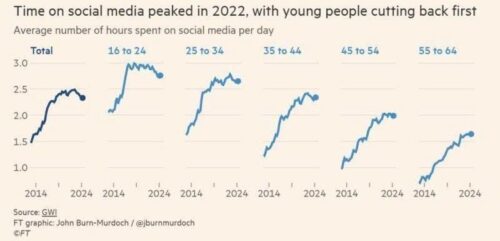
Tiktokización: el feed ya no es una plaza pública; es una cinta transportadora de contenido. Da igual a quien sigas. Esto es lo que te meteremos unidireccionalmente garganta abajo según el perfil que hemos hecho de ti.
Los algoritmos priorizan anuncios, colaboraciones pagadas, bots e IA o directamente p*t*s n*z*s locos y el contenido orgánico se vuelve residual. Menos conversación y menos “vida personal” publicada; más consumo pasivo.
Ya no son redes sociales; son plataformas de contenido.
Si quieres alojar a una comunidad de verdad, toca sacar el centro de gravedad « al bosque oscuro »: canales propios (newsletter, web, lista), espacios semiprivados, mensajería instantánea, comunidades pequeñas y cuidadas.

CARREFOUR, SUNDAY 12 P.M.
For the past ten years, every Sunday at 12 p.m. when the weather is sunny, the photographer, seated on the roof of his van about three and a half metres above the ground, has been welcoming people who come to spend their day off in the Carrefour car park in El Plat del Llobregat, on the outskirts of Barcelona, when the shopping centre is closed.
GPTZero detects AI content from ChatGPT, GPT-5, Gemini, and checks writing quality to make every word worth reading.
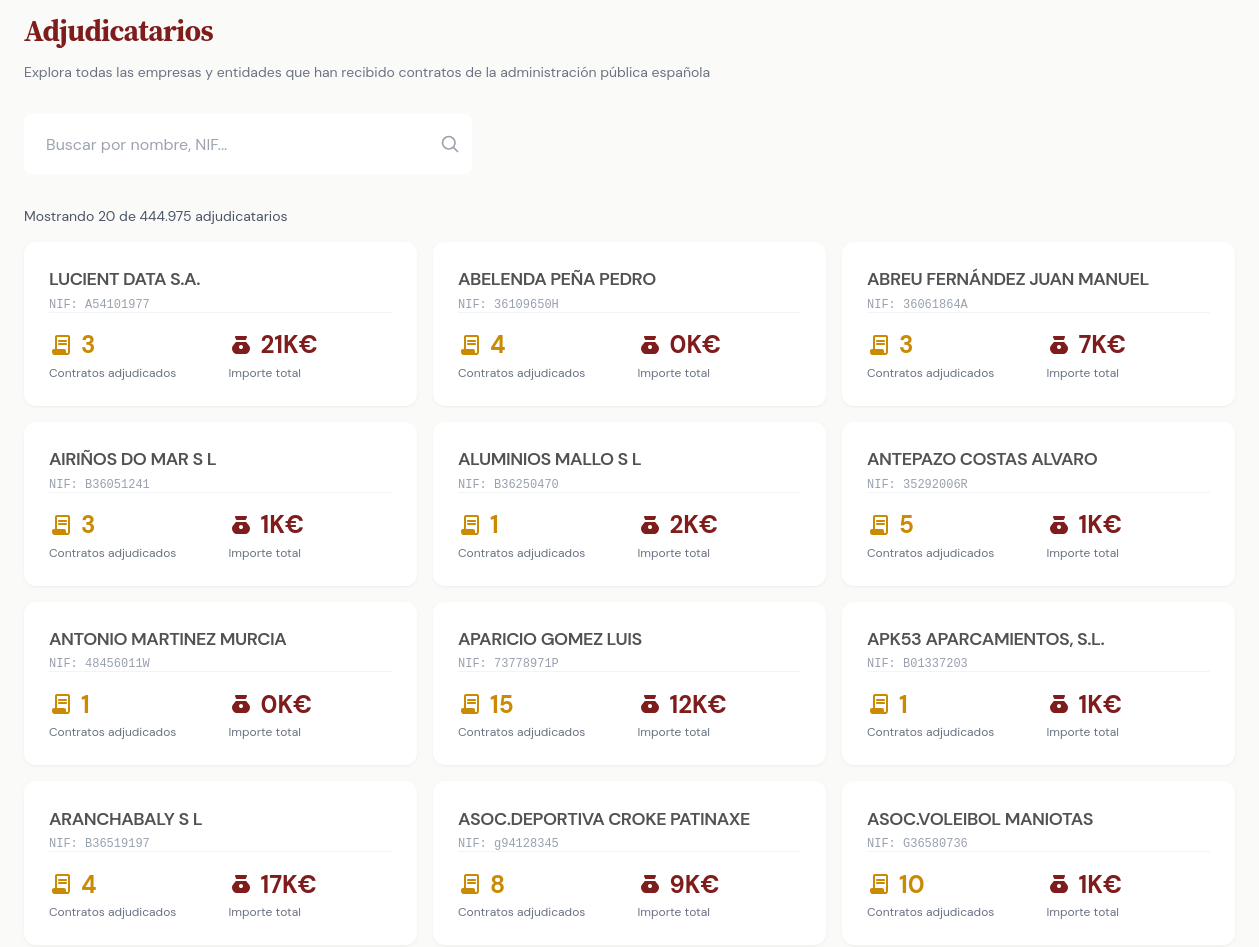
Las administraciones públicas están obligadas a publicar sus contratos menores. A lo que no están obligadas es a hacerlo fácil. Plataformas que fallan, formatos imposibles, límites técnicos absurdos para complicarte la vida. Esta herramienta existe para que no tengas que pelearte con un sistema diseñado para que te rindas. Tu dinero, tu derecho a saber.
Link rot (also called link death, link breaking, or reference rot) is the phenomenon of hyperlinks tending over time to cease to point to their originally targeted file, web page, or server due to that resource being relocated to a new address or becoming permanently unavailable. A link that no longer resolves at the intended target may be called broken or dead.
The rate of link rot is a subject of study and research due to its significance to the internet’s ability to preserve information. Estimates of that rate vary dramatically between studies. Information professionals have warned that link rot could make important archival data disappear, potentially impacting the legal system and scholarship.
Identify the jail you want to apply the ban to:
sudo fail2ban-client status
Run the following command, replacing with the jail’s name (e.g., sshd) and with the IP you want to block:
sudo fail2ban-client set banip
Check if the IP is now listed under the banned IP list for that jail:
sudo fail2ban-client status
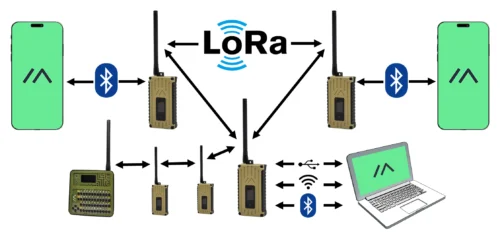
An open source, off-grid, decentralized, mesh network built to run on affordable, low-power devices
Meshtastic® is a project that enables you to use inexpensive LoRa radios as a long range off-grid communication platform in areas without existing or reliable communications infrastructure. This project is 100% community driven and open source!

Como en el resto de películas de la serie de Indiana Jones, el objeto buscado (el Arca de la Alianza, las piedras Shankará o la Calavera de Cristal) no es más que un McGuffin (una excusa argumental introducida para hacer avanzar el guion, utilizado el término acuñado por Alfred Hitchcock), tal como reconoció el propio George Lucas, por lo que la búsqueda del Grial no es más que una excusa para buscar al padre. Según Lucas, la película trata del reencuentro entre un padre y su hijo y no de la búsqueda de un objeto. La relación distanciada que Indiana mantiene con su padre es un tema que resulta común en otras películas de Spielberg, tales como E.T., el extraterrestre o Hook. El propio Spielberg tenía una relación difícil con su padre

Dans un futur proche, alors que les datas se multiplient, la mémoire de l’humanité devient un extraordinaire enjeu. Après l’adaptation en BD de « Sukkwan Island » de David Van, et « Paiement accepté », son clin d’œil pop au cinéma, le jeune et talentueux dessinateur signe l’une des meilleures BD de l’année.
A l’heure du cloud, et si la mémoire artificielle venait à manquer ? En 2055, Yves Mathon travaille dans une entreprise chargée de trier ce qui sera utile à l’avenir pour la société ultra contrôlée dans laquelle il vit. Exemple : le film « 2001, l’Odyssée de l’espace» : on garde ou on jette ?

En 2120, le data est devenu si volumineux qu’il faut commencer à effacer des données. Toute archive frappée d’un visa d’élimination par le corps des « Prophètes », chargé d’opérer les choix cruciaux, doit être supprimée. Yves, archiviste humaniste du Bureau des Essentiels, ne peut s’y résoudre. Pour les sauver de l’oubli, il sauvegarde clandestinement certaines données, plus poétiques que politiques, et les rapporte chez lui pour les stocker dans la mémoire de Mikki, son robot domestique. Une infraction grave à l’éthique de sa profession. Les progrès de l’intelligence artificielle ayant par ailleurs permis de confier la charge de la gestation pour autrui (GPA) aux machines, Mikki, bot hermaphrodite, porte l’enfant d’Yves et Julia, son épouse.

Tomemos ese viejo ejemplar que anda por casa. Rebosa anuncios de compra y venta de vivienda, de productos de segunda mano, de empleo. Cada uno de esos clasificados acabó convirtiéndose en un servicio digital (Idealista, Wallapop, LinkedIn) que los responsables de la prensa no supieron conservar.
GeoPandas can read almost any vector-based spatial data format including ESRI shapefile, GeoJSON files and more using the geopandas.read_file() command
This post walks through the steps I followed to build a web-based map using Python, Folium, and GeoPandas — from handling shapefiles to adding custom tooltips, interactive toggles, and responsive feedback using JavaScript libraries like AlertifyJS.
In this tutorial, we’ll explore how to create and visualize GeoJSON data, a popular open-source format for representing geographic data, using geojson.io and Folium in Python.
…the geodatasets package. This new package, separated from the main GeoPandas library, focuses on access to and management of spatial datasets. We’ll walk you through installing geodatasets and demonstrate how it complements GeoPandas in handling geospatial information.
A weblog about simple, useful software.
Vite is a blazing fast frontend build tool powering the next generation of web applications.

Dans le premier tome, Riad décrit la rencontre de ses parents à Paris, et leur installation en Libye, puis au village de Ter Maaleh en Syrie. Il pose les bases des thématiques principales de la série : l’image du père, le contexte géopolitique au Moyen-Orient de l’époque et le contraste entre les cultures et traditions européennes et orientales.
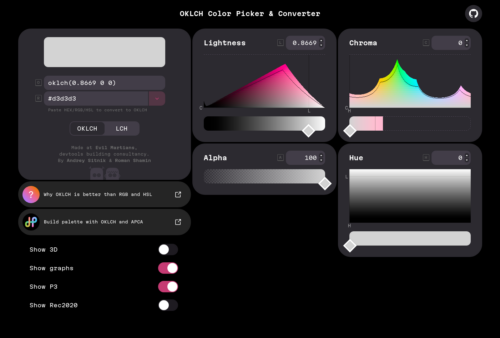
oklch() is a new way to define CSS colors. In oklch(L C H) or oklch(L C H / a), each item corresponds as follows:
L is perceived lightness (0–1). “Perceived” means that it has consistent lightness for our eyes, unlike L in hsl().C is chroma, from gray to the most saturated color.H is the hue angle (0–360).a is opacity (0–1 or 0–100%).The benefits of OKLCH:
hsl(), OKLCH is better for color modifications and palette generation. It uses perceptual lightness, so no more unexpected results, like we had with darken() in Sass.rgb() or hex (#ca0000), OKLCH is human readable. You can quickly and easily know which color an OKLCH value represents simply by looking at the numbers. OKLCH works like HSL, but it encodes lightness better than HSL.
The Conversation is a 1974 American neo-noir mystery thriller film written, produced, and directed by Francis Ford Coppola. It stars Gene Hackman as surveillance expert Harry Caul who faces a moral dilemma when his recordings reveal a potential murder.
Modern Next.js applications are built on a robust foundation of React and Next.js-specific hooks. These hooks help manage state, handle routing, perform data fetching, and more — all while keeping your components clean and performant. In this post, we’ll explore 20 powerful hooks that are used across most Next.js projects and explain how to use them effectively.
ratgdo is a WiFi control board for your garage door opener that works over your local network using ESP Home or HomeKit.

At FULU, we believe that people should control the tech they bought and own.