

Este post es parte de la serie Investigación colaborativa, divertida, barata, transmedia. Otras formas de entender la investigación, publicada a modo de cruce de posts entre el blog de Pablo Rey y el mío. Este trabajo se enmarca dentro de un estudio sobre Investigación en red coordinado por Mayo Fuster Morell parte de un proyecto más amplio sobre Juventud, Internet y Politica bajo la dirección de Joan Subirats en el marco del grupo IGOPnet.cc, con la colaboración de Montera34, para la Fundación Museo Reina Sofía sobre adolescencia y juventud.
Durante el año 2012 participé en dos eventos que tuvieron la investigación como trasfondo: el encuentro #meetcommons desarrollado en Madrid en abril, y el congreso Equiciudad 2012 celebrado en San Sebastián en diciembre. El primero, autoorganizado, con un programa abierto que se definió colectivamente durante el mismo evento, sin financiación. El segundo, auspiciado por la Universidad del País Vasco (UPV), y organizado en colaboración entre la UPV y la asociación Sinergia Sostenible, un congreso consolidado y reconocido en su ámbito, ya en su segunda edición.
Aunque al principio no me di cuenta, la asistencia a ambos eventos en el mismo año me ha permitido experimentar una manera de investigar «sin darme cuenta»: una investigación que tiene mucho de colectiva, que aprovecha los archivos personales como materia prima para elaborar conclusiones, que trabaja a partir de las experiencias vividas contenidas en esos archivos para generar relatos.

Cartel de #meetcommons 2012 realizado por Lacasinegra.
#meetcommons
En noviembre de 2011, Domenico Di Siena empezó a emitir unas sesiones en streaming, a las que llamó Think Commons. Cualquier interesado podía asistir a la sesión y participar activamente en ella mediante un chat. Domenico lo definió entonces como «Un entorno transmedia que promueve el debate y genera conocimiento sobre procomún, creación colectiva, colaboración, cultura libre y open government». Cada miércoles a las 19.30 horas, GMT+2, Domenico emitía una nueva sesión, junto a una persona invitada.
Tras cinco meses de sesiones, #meetcommons se pensó con el objetivo de reunir presencialmente a la comunidad que se había ido consolidando en torno a Think Commons. Además de asistir a las sesiones de los miércoles, empezamos a debatir por videoconferencia, correo electrónico y Twitter la manera de hacer viable un encuentro presencial en Madrid, lugar donde residía la mayor parte de la, por entonces ya autodenominada, «comunidad thinkcommons». Así se acordó que durante el fin de semana del 20 al 22 de abril de 2012, nos juntaríamos para «explorar nuevos contextos para el aprendizaje, la interdisciplinariedad, el trabajo colaborativo y la cultura libre», movidos por la necesidad de redefinir nuestra «capacidad de actuar y de disfrutar de nuestro entorno según dinámicas de auto-organización». El encuentro se nos hacía necesario tras llevar un tiempo experimentando cómo otros modelos habían perdido eficacia para nuestras prácticas.
Autoorganización
#meetcommons partía con unos condicionantes fuertes: no había financiación ni tiempo para conseguirla, y el tiempo requerido para su organización tendría que salir de nuestro tiempo libre. Así la autoorganización fue, además de algo que nos apetecía experimentar, una característica obligada para la viabilidad del encuentro, una cuestión estratégica. #meetcommons sería posible únicamente si los participantes eran también organizadores, ponentes y financiadores.
Desde un primer momento se trabajó con documentos abiertos de edición colaborativa, lo cual permitió definir necesidades, formar la comunidad de interesados y repartir responsabilidades sin necesidad de reuniones. Un documento abierto en PiratePad ayudó a concebir la escala del evento, evaluar a qué nos enfrentábamos. Inicialmente bastó con una lista de tareas imprescindibles, una lista de la gente que iba confirmando asistencia, y otra de la gente que necesitaba un lugar para dormir.
Marina Blázquez, una de las asistentes asiduas a las sesiones Think Commons, definió unas categorías para repartir responsabilidades y organizar la participación. El grupo Hello_commons se encargaría de la recepción en el evento, de situar a los asistentes a su llegada, de informarles del funcionamiento del espacio; el grupo Telling_commons de la difusión; Ambience_commons de acondicionar el espacio de actividades; Camping_commons de la infraestructura y limpieza de la zona para pasar la noche; dentro del grupo Activity_commons se coordinarían las personas encargadas de dinamizar y moderar las distintas actividades; y desde Money_commons se llevaría la contabilidad para asegurar una transparencia total en la gestión de los recursos.
#meetcommons costó 845,79 euros. Todo el dinero salió de los bolsillos de los participantes, exáctamente 845,03 euros. El pequeño desfase de 76 céntimos, se debe casi con toda seguridad a un error de contabilidad. Aproximadamente la mitad de los ingresos (403,03 euros) se obtuvo mediante un botón de donación Paypal en la página de Think Commons, y el resto se recogió en metálico durante el fin de semana. Se puede consultar la contabilidad completa del evento, publicada en un documento compartido para que todos los participantes o cualquier interesado pudiese saber en qué se estaba gastando el dinero.
Las aportaciones eran libres, pero se sugirieron unas cantidades para que cada asistente tuviera una referencia. Las estimaciones se hicieron en función del número de comidas. Se habilitó otro documento compartido en el que cada persona apuntaba en cuántas comidas participaría y lo que aportaba. De esta manera se pudo tener una idea de para cuántas personas había que cocinar.
Abierto, en el sentido de indefinido
El ámbito temático estaba definido de manera muy genérica («nuevos contextos para el aprendizaje, la interdisciplinariedad, el trabajo colaborativo y la cultura libre»), y tras algunos intentos de definir un programa más o menos cerrado, se llegó a la conclusión de que sería más eficiente y flexible dedicar la primera sesión del propio encuentro para evaluar los intereses de los asistentes y definir cada una de las sesiones posteriores. Se hizo una programación de los tres días de encuentro, en cualquier caso, pero no en función de los contenidos; el programa se pensó desde el ritmo, los tipos de actividad y los ambientes que se querían generar. Se intentó crear espacios y situaciones variadas para que los encuentros entre los participantes también lo fueran. Así se fijaron y secuenciaron unas «franjas de actividad» estimando el tiempo necesario para cada una de ellas: ronda de presentaciones, debate colectivo, debate por grupos, proyecciones, fiesta, tiempo libre… Posteriormente se definió una metodología para reglar los debates colectivos, para intentar evitar el monopolio de la palabra. Por analogía con el medio en el que se había producido una buena parte del debate, Twitter, se limitaría cada intervención a 140 segundos. En el caso de que una intervención estuviera dirigida a una persona en concreto, se permitiría una única réplica directa e inmediata para cada intervención sin necesidad de esperar turno, también de 140 segundos.
Desde el principio #meetcommons se pensó como un espacio de encuentro, pero sobre todo como un espacio de experimentación, como un prototipo de encuentro con una metodología de organización y producción en pruebas. Parte del debate fue autorreferencial, y habló de las capacidades y fallos del «modelo #meetcommons», de sus posibilidades y del interés de replicarlo.
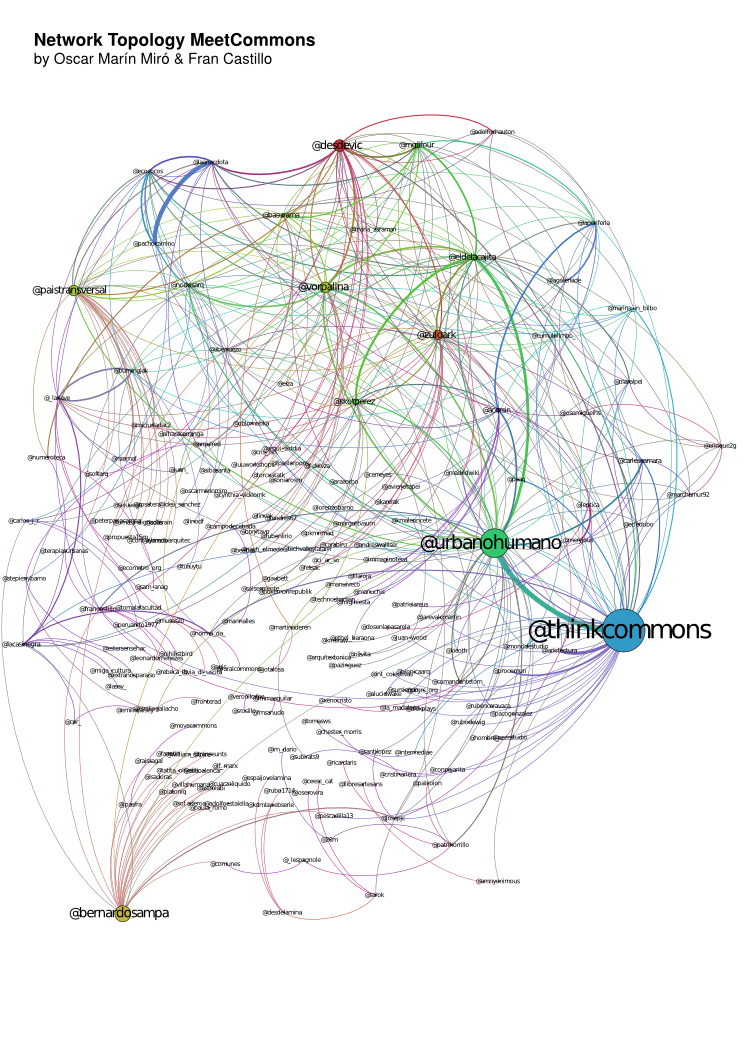
Red de usuarios #meetcommons 2012, por Oscar Marín Miró y Fran Castillo.
Documentación colaborativa
Igual que se intentó evitar el monopolio de la palabra, se trabajó para evitar la apropiación del relato del evento. Dentro del grupo Telling_commons se pensaron herramientas para recopilar los relatos individuales, y crear una documentación colectiva. La materia prima de la documentación fueron los archivos personales de los participantes, fundamentalmente sus líneas temporales de Twitter.
El colectivo Lacasinegra, un colectivo artístico dedicado a la investigación y experimentación audiovisual, con el cine como punto de partida, había creado el año anterior a raíz de las protestas del 15M una aplicación para «expandir el significado de las protestas globales a través de sus imágenes». La aplicación Bannertube fue ideada para recopilar eslóganes del movimiento 15M, que los usuarios de Twitter subían a sus cuentas en forma de imágenes, y relacionarlos con vídeos de la plataforma Youtube mediante un algoritmo que usaba la API de la plataforma de vídeos. Como explica Lacasinegra en la página de la aplicación, de esta manera «se generan asociaciones narrativas completamente heterogéneas» (la negrilla es mía). Lacasinegra desarrolló una versión de Bannertube para #meetcommons en el que todos los tuits publicados con el hashtag #meetcommons y que incluyesen una imagen se recopilaron.
Como parte de este grupo de documentación, y en colaboración con Pablo, coautor de este texto, desarrollé una herramienta que posteriormente llamamos Eventweet, pensada para documentar eventos de manera colaborativa usando Twitter. El funcionamiento es sencillo: Eventweet recopila todos los tuits con un hashtag determinado, el acordado para hablar del evento en Twitter, permitiendo consultar la línea temporal completa desde el nacimiento del hashtag. La idea de fondo es eliminar el carácter efímero de Twitter, cuyo motor de búsqueda únicamente indexa los tuits publicados durante los últimos siete días, y que para la línea temporal de un hashtag aplica la misma limitación.
Twitter es una herramienta que estructuralmente no está pensada para generar un archivo sino para generar narraciones plurales y distribuidas, inmediatas y efímeras, una maraña de historias. Eventweet recoge el material subido a Twitter en una base de datos propia, permitiendo consultar la línea temporal completa del evento a través de su hashtag, pero también la narración individual de cada usuario. Así se pueden obtener cada uno de los hilos de la narración por separado.
Desde el principio se buscó visibilizar la comunidad de personas que estaban alrededor de Think Commons y la que se formaría en #meetcommons. El Eventweet de #meetcommons se concibió como una base de datos de los miembros de esa comunidad y de un cierto reflejo de la actividad de cada uno en ella, tomando como parámetro su actividad en Twitter. Complementariamente, Fran Castillo y Óscar Miro, desarrollaron una visualización de las relaciones entre los miembros de la comunidad, también en función de su actividad en Twitter.
Si pensásemos en un tejido a base de hilos de narración, podríamos decir que Bannertube nos muestra la prenda acabada y nos sugiere posibles usos, en cambio Eventweet la deshace para mostrarnos cada hilo con el que se ha tejido.
Tanto Bannertube como Eventweet recopilan indiscriminada y masivamente datos relacionados con #meetcommons que encuentran en archivos personales. Luego los ordenan, cada herramienta según su lógica, y los ponen a disposición como material investigable.
Cada uno de los asistentes al evento, cada uno de los que no asistieron presencialmente pero participaron en los debates previos, cada persona que utilizó el hashtag #meetcommons contribuyó a la documentación colectiva, investigó sin darse cuenta.
Este post es la respuesta al publicado por Pablo Rey en su blog el 21 de enero de 2014: Investigar (es ir) haciendo y compartiendo: Demo or die. La próxima entrega de la serie se publicará en numeroteca.org el martes 28 de enero de 2014.
Bibliografía
Corsín Jiménez, Alberto (2013) «The betagrammatic city: atmospheric iconism and urban hacking». Artículo pendiente de revisión por pares.
Di Siena, Domenico (2012) «Think Commons», en Música para camaleones. El black álbum de la sostenibilidad cultural. Edición Transit Projects.
Versión digital (consultada el 3 de septiembre de 2013): http://urbanohumano.org/social-tecnology/musica-pra-camaleones-think-commons/
7 comentarios
Mmmmm, aqui vengo yo a plantear mis dudas.
Vale que, como decia Pablo en la entrada del martes pasado en su blog, investigar para craer las herramientas que necesitas para tu investigación, es investigación. En este caso concreto veo claramente que el desarrollar herramientas como bannertube o eventweet, son parte de una investigación que además, luego (o antes) han servido como herramientas en otros entornos, pero a partir de aqui ya me entran dudas de si organizar y participar en un evento asi, sea meetcommons o equiciudad al que también citas, es investigar.
Está claro que quien fue al meetcommons, y participó en todo ese fantastico sarao que cuentas aprendio de lo lindo, aprendio a hacer probablemente cosas que no sabia hacer, además en este caso a hacerlas entre muchos, aprendio que se pueden hacer las cosas de otra manera, aprendió un montñon de los demás… pero eso, es que lo leo, lo miro y lo pienso y me digo a mi mismo si esto no es aprendizaje, pero saltas del aprendizaje a la investigación enseguida, y esa es mi duda.
Aprendizaje es investigación? O son cosas distintas, está claro que investigando, aprendes, pero aprendiendo investigas. Entiendo que es dificil hacer una linea clara entre las dos cosas, pero yo entiendo, aunque igual es precisamente de lo que se trata de «desaprender» en esta serie de articulos, que la investigación es algo más, no? No se, quiero más chavales, esto esta muy interesante.
Gracias por el comentario hans.
Podemos diseccionar un proceso de investigación, simplificándolo mucho, en la recopilación de datos, en su análisis y en la obtención de conclusiones, lecturas o demostraciones de la tesis.
Asumiendo que cualquiera que asistió a #meetcommons tiene una presencia en internet y volcó algún momento vivido en uno de sus espacios digitales, podemos decir que participó de la investigación, en el sentido de que su archivo personal forma parte de los datos recopilados por las herramientas. Si además trasteó con cualquiera de las herramientas quizás sacó alguna conclusión, utilizando los datos y el análisis previo. E incluso si, como en mi caso o en el de Lacasinegra o de Fran y Óscar, prefirió analizar datos y hacer una herramienta o una visualización, también investigó.
Así que sí, quiero decir investigación y no aprendizaje :)
La idea de fondo es que esta otra investigación es colectiva y cotidiana, y ya no es necesario un laboratorio o un centro de investigación para investigar, tampoco hace falta ser académico o científico.