


@numeroteca utilizando su magia gráfica para transformar a Marti y Doc.
Estamos a principios de 2007. España va bien. La burbuja es una idea en boca de pesimistas agoreros. Todavía no existen conceptos como vieja política ni casta. Aún no se usa la palabra conseguidor, ni mamandurria. Bankia todavía se llama Caja Madrid. El año siguiente estalla la burbuja inmobiliaria pero no es hasta 2014 que se destapa el escándalo de las tarjetas black: más de 15 millones de euros gastados por 86 consejeros y ejecutivos de Caja Madrid usando tarjetas black. Volviendo a 2007, ¿en qué se estarían gastando los consejeros de Caja Madrid sus tarjetas black? ¿Qué comprarían entonces, cuando todavía no había estallado la burbuja? ¿Cómo sería la vida un día como hoy pero hace diez años de uno de estos señores?
El pasado diciembre en Montera34, Pablo y yo hemos desarrollado Black to de Future. Una sencilla web y un bot de twitter que relatan un día en la vida de los señores de las black a través de sus gastos: concretamente un día como hoy de hace diez años.
En este post voy a contar el making-of técnico del proyecto. Pablo ha escrito otro post en el que relata cómo ha evolucionado este experimento de small data, como él lo llama, y cómo surgió:
Desde hace un tiempo nos rondaba en Montera34 a Alfonso y a mi la idea de ponernos de nuevo con los datos de las tarjetas black. El juicio estaba llegando a su fin, todavía teníamos un pequeño margen antes de las deliberaciones finales y la sentencia.
En vez de analizarlos en su conjunto otra vez ¿por qué no cambiar la forma de acercarse a los datos y fomentar ver el detalle de cada gasto? Nos parecía interesante poder tratar los gastos uno a uno y entender cuándo y cómo sucedían. Un ejercicio de «small» data para hacer mininarrativas con tamaño tuit de cada gasto.
La web
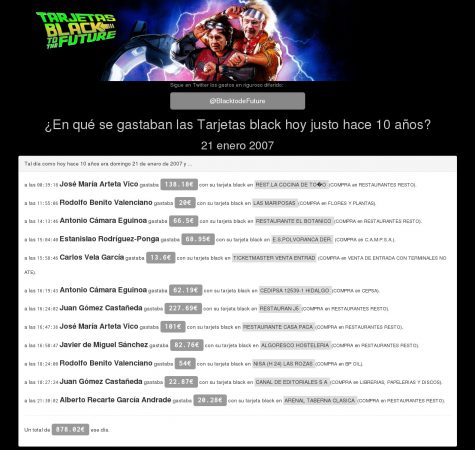
La web de Black To De Future publica todos los gastos de un día de hace exactamente diez años. Un script de PHP recorre el archivo CSV con todos los gastos y muestra los del día correspondiente. No tiene más.
Aunque cuando se visita se ven los gastos de hace diez años, se pueden consultar los gastos de cualquier día añadiendo a la URL el parámetro dia. Por ejemplo, para ver los gastos del día de San Valentín de 2005: http://lab.montera34.com/blacktodefuture?dia=14-02-2005
El código se puede consultar y descargar en github.
El bot de Twitter
Para seguir los gastos en riguroso diferido de diez años hemos abierto la cuenta de Twitter @BlacktodeFuture en la que se van publicando «en tiempo real».
https://twitter.com/BlacktodeFuture/status/822125367838248961
https://twitter.com/BlacktodeFuture/status/822123351309254656
https://twitter.com/BlacktodeFuture/status/822110251994464256
https://twitter.com/BlacktodeFuture/status/822109746958311424
De la publicación se encarga un bot programado en Python. Para conectar con twitter usa la biblioteca python-twitter, y para programar la publicación en el momento preciso la biblioteca schedule. Preferimos utilizar esta biblioteca de python en vez del cron de linux para no crear una dependencia externa más (qué sistema utilizar para programar tareas es todo un debate).
El script de Python consiste en una función que recorre el archivo csv con los gastos, y si encuentra alguno justo hace diez años lo publica en la cuenta @BlacktodeFuture de Twitter. schedule lanza la función cada minuto.
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
#Load required modules
import twitter
import csv
from datetime import datetime
#from time import sleep
import time
from dateutil.relativedelta import relativedelta
import schedule
# Twitter API configuration
config={}
execfile("TweetConfig.py", config)
# Twitter API authentication
api = twitter.Api(consumer_key=config['consumer_key'], consumer_secret=config['consumer_secret'], access_token_key=config['access_key'], access_token_secret=config['access_secret'])
# Tweet expense when correct time
def tweetExpense():
# date
now = datetime.now()
then = now - relativedelta(years=10)
then_date = then.date().strftime("%Y-%m-%d")
then_time = then.time().strftime("%H:%M")
# Open data file
filename = "data/" + then.date().strftime("%Y-%m") + "-data.csv"
with open(filename, 'r') as csvfile:
spamreader = csv.DictReader(csvfile)
# csv rows loop
for row in spamreader:
hora = row['hora'][:-3]
if then_date == row['date'] and then_time == hora:
comercio = row['comercio']
importe = row['importe']
quien = row['quien']
status_text = 'Hace 10 años ' + quien + ' gastaba ' + importe + '€ con su tarjeta black en ' + comercio
#print (len(status_text))
status = api.PostUpdate(status_text)
#print(status.text)
#print(status_text)
# Schedule tweetExpense every minute
schedule.every(1).minutes.do(tweetExpense)
while True:
schedule.run_pending()
time.sleep(15)
Para que cada vez que el script busca gastos no tenga que recorrer los cerca de 75.000 registros que contiene el CSV con los gastos desde 2003 a 2012, un script de bash ha dividido el enorme CSV, generando un archivo para cada mes:
#!/bin/bash
#
# This script splits huge data.csv file
# into one file per month group of files
#
###
# VARS
FILE="data/data.csv"
LINE=0
PREFIX_OLD=""
while read row; do
if [[ $LINE == 0 ]]
then
HEADER=${row}
else
PREFIX=${row:0:7}
if [[ $PREFIX != $PREFIX_OLD ]]
then
echo $HEADER > data/${PREFIX}-data.csv
fi
echo ${row} >> data/${PREFIX}-data.csv
fi
PREFIX_OLD=$PREFIX
((LINE++))
done <${FILE}
Un demonio de linux (systemd) mantiene el script a la escucha en segundo plano, y asegura el inicio del script si se reinicia el sistema o hay algún fallo. Existe la biblioteca python-systemd que permite crear el demonio en systemd desde el propio script.
Si alguien quiere usar el script, lo puede encontrar en github, donde hay unas instrucciones mínimas para ponerlo en marcha en un sistema Linux Debian.
Conclusiones: cuando la teoría de lo abierto funciona
Idea: visualizar pocos datos en vez de muchos ¿en qué gastaban el dinero los de las #TarjetasBlack hace justo 10 años? cc @skotperez
— numeroteca (@numeroteca) December 1, 2016
Éste es el primer tuit de la conversación que mantuvimos Pablo y yo desde el principio de proyecto en Twitter. Nada más tener lista una versión muy básica la web, hubo más gente que se unió a la conversación y aportó ideas: el nombre de Black to de Future se le ocurrió a @guillelamb, y la idea de hacer un bot de Twitter se fraguó en una conversación entre Pablo, aka @numeroteca, y @martgnz. El proyecto no habría sido el mismo si lo hubiésemos pensado Pablo y yo solos.
Por otro lado, hemos puesto en marcha la infraestructura del proyecto en poco tiempo: el código de la web es una variación de un script que usamos en Montera34 para insertar contenido de manera automática en un WordPress a partir de un CSV. A su vez el bot de Twitter reutiliza el código del proyecto El cuarto de basuras de la modernidad que hicimos entre Obsoletos y Basurama, en el que imprimíamos en tiempo real varios hashtags con impresoras térmicas:
Output del script de python de las #obsoprinters de #bauhaus, funcionando crt @obsoletos_org pic.twitter.com/WJtznoK7TA
— Alfonso @skotperez (@skotperez) June 11, 2015
Abrir un proyecto desde el principio, echar a andar rápidamente con prototipos y no esperar a tener modelos «acabados», reutilizar el trabajo ya hecho (por otros o por uno mismo): hemos experimentado la potencia de desarrollar un proyecto de manera abierta y colaborativa. Nada nuevo, pero da gusto ver que la teoría que hemos leído tantas veces funciona.
5 comentarios
No usáis librerías (bookshops) sino bibliotecas (libraries): el castellano es código también abierto, lo que no significa arbitrario (lo que sabréis bien si trabajáis con python y similares).
Pues es cierto. Como no hacemos cosas por defecto, sino por omisión. Hay que estar muy atentos para no repetir traducciones que leemos continuamente. ¡Corregido!
¡El proyecto me mola todo! ¡Enhorabuena!
Lo de partir el fichero y recorrerlo lo veo poco limpio. Una propuesta de reimplementación es meter todo el csv en una base de datos (puede ser sqlite, para no tener que depender de que haya un mysql o un postgres instalado) y hacer peticiones SQL para pillar todos los datos de un día…
Pues gracias por la sugerencia Rafa. Y por la explicación más detallada que me has dado por videollamada :) Para el próximo proyecto lo tendremos en cuenta.
Sobre bases de datos ligeras, para entornos en los que no interesa o no se puede instalar un servidor de base de datos, publiqué algo hace un tiempo en el blog. Hay varios CMS, como Jekill, que usan estas alternativas ligeras como base de datos, ¿qué te parecen?