

Este post es parte de la serie Investigación colaborativa, divertida, barata, transmedia. Otras formas de entender la investigación, publicada a modo de cruce de posts entre el blog de Pablo Rey y el mío. Este trabajo se enmarca dentro de un estudio sobre Investigación en red coordinado por Mayo Fuster Morell parte de un proyecto más amplio sobre Juventud, Internet y Politica bajo la dirección de Joan Subirats en el marco del grupo IGOPnet.cc, con la colaboración de Montera34, para la Fundación Museo Reina Sofía sobre adolescencia y juventud.
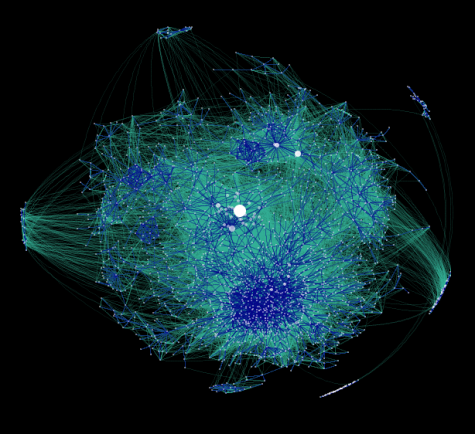
Mapa de la blogosfera elaborado por Matthew Hurst. Cada punto representa un blog; su tamaño depende del número de enlaces entrantes. Cada línea representa un enlace; las azules representan enlaces recíprocos.
voragine.net es mi blog personal que inauguré en 2007 con la idea de crear mi propio archivo de snippets. Entonces, al igual que ahora, estaba fascinado por la capacidad de los programadores de compartir pequeños fragmentos de código reutilizables, autónomos y funcionales dentro de su contexto, que llamaban snippets. La potencia de esta manera colectiva y distribuida de programar me maravillaba, y quería contribuir a ella, después de haberla aprovechado ampliamente.
Los snippets ahorran una cantidad de tiempo importante a cualquier programador: ésta es una de las razones por las que yo y muchas otras personas los recopilamos. Hoy día los buscadores permiten encontrar estas soluciones relativamente rápido, pero tenerlas bien ordenadas siguiendo criterios propios, y clasificadas en un único sitio web, hace de la búsqueda algo trivial e inmediato. De esta manera mi blog se ha convertido en una caja de herramientas para programar, un banco de recursos al que acudo a diario. Podríamos decir que es una memoria auxiliar, un disco duro externo en el que guardo todo lo que no soy capaz de recordar.
En programación, la antigüedad del código es un dato muy importante: puede suponer la diferencia entre una solución que funcione y otra que genere un conflicto en un programa por razones de incompatibilidad con algún otro trozo de código. Una versión antigua de un programa puede contener algún agujero de seguridad, que en versiones más actuales se haya solucionado. Debido a estas razones el orden cronológico que predomina en los blogs es adecuado para archivar código: rápidamente se puede saber cuándo un snippet ha sido añadido al blog, que muchas veces es equivalente a saber cuándo ha sido probado por el autor del blog que lo publica, lo cual da una idea del momento en el que seguro funcionaba.
Cuando nos descargamos un archivo, por ejemplo una canción, de una red de intercambio P2P, descargamos cada trocito del archivo de un ordenador diferente conectado a la red. Análogamente para desarrollar una aplicación usamos multitud de snippets que vamos encontrando en diferentes lugares de internet. A diferencia de la canción que va ensamblando un gestor de descargas automáticamente, los trozos de código los tenemos que buscar y ensamblar manualmente. Por esta razón las recopilaciones de snippets de un blog son tan útiles: es como tener la canción completa en nuestro ordenador para poder escucharla. El trabajo queda hecho y no hay que volver a repetirlo, y además puede servir a otros programadores que ya no tienen que hacerla. Los snippets hacen de la blogosfera un gran repositorio de código distribuido.
Una características interesante de los blogs es que pueden comunicarse entre ellos automáticamente. Imaginemos que encuentro un snippet en algún otro blog, al que hago alguna modificación para que se ajuste a mis necesidades y después lo publico en el mío. Al publicarlo acreditaré convenientemente al autor del código encontrado enlazando a su página. Este enlace se llama técnicamente backlink, un enlace entrante a la página donde encontré el código. Al crear el enlace, mi blog enviará una notificación a la página enlazada, un trackback, que a su vez notificará al autor. De esta manera el creador del snippet puede acceder al código mejorado por mí. Este proceso puede repetirse indefinidamente, generando un código cada vez más completo.
Estas dinámicas de programación distribuida hacen de los blogs, archivos personales de código en este caso, nodos de una investigación en red a escala mundial verdaderamente productiva.
Bibliografía
Sánchez Uzábal, Alfonso (2013). «Lógica distribuida para la autoorganización ciudadana», en Ciberoptimismo, conectados a una actitud. Edición Fundación Cibervoluntarios. Versión digital (consultada el 3 de septiembre de 2013): https://voragine.net/cultura-libre/logica-distribuida-para-la-autoorganizacion-ciudadana
Este post es la respuesta al publicado por Pablo Rey en su blog el 11 de febrero de 2014: Liveblogging, cómo documentar en directo. La próxima, y última entrega de la serie se publicará en numeroteca.org y voragine.net el martes 18 de febrero de 2014.
Entregas anteriores de la serie:
- Investigar (es ir) haciendo y compartiendo: Demo or die, en numeroteca.org.
- Investigar sin darse cuenta: #meetcommons, acción y documentación colectiva, en voragine.net.
- Investigar (es ir) haciendo y compartiendo: Public Lab y PageOneX, en numeroteca.org.
- Investigar sin darse cuenta: archivos personales, en voragine.net.
- Liveblogging, cómo documentar en directo, en numeroteca.org.
- Espacios autónomos de experimentación e investigación, en voragine.net.
- Investigación Sprint vs. Investigación de largo recorrido, en numeroteca.org
3 comentarios